最近機械学習で為替予測をしています。あまり情報を出すとエッジが無くなるのではないかと思ってあえてほとんど情報を出してこなかったんですが、よく考えるとそもそも機械学習の話題を理解できる人の母数が少なく、よくあるゴールデンクロスみたいな手法と違って誰でも理解できて再現できるわけじゃないと思うのである程度出していくことにしました。
やってること
機械学習(Deep Learning 含む)で為替予測をやっています。なぜ株ではなく為替かというと、レバレッジが効くのと MetaTrader や cTrader みたいな自動取引ができるプラットフォームがあるからです。実際には株のほうが簡単っぽい雰囲気を感じます。
データの取得
まずは為替の価格データが無いと始まらないのでどうにかして用意します。自分は cTrader (というか cAlgo) でデータを CSV に落とす cBot 作ってバックテストで実行して取得しました。最初は 5 分足のデータを取ってましたが、現在は 1 分足のデータを取って使っています。1 分足のデータがあれば 5 分足のデータは作れますし、1 分足のほうがデータ量が多いのが理由です。
ただ cTrader は新しめのプラットフォームなので、過去データが 2011 年ごろからしかないです。もっとデータが欲しいのであれば MetaTrader あたりでデータ取ったほうがいいと思います。ちなみに MetaTrader で取れる過去データは信頼性がアレみたいな話があります。
データは OHLC + Volume + Time を取りました。色んなテクニカルインディケーターの値も含められますが、OHLC + Volume + Time だけあれば各種インディケーターの値は後からでも計算できるので必要ありません。というかインディケーターの値は必要ないと思っています。これについては後述します。
特徴量選択
データを用意したところで Deep Learning のモデルに入力する特徴量を決めます。よく見るのがテクニカルインディケーターの値を特徴量にしているものですが、そもそもテクニカルインディケーターの値は価格や取引量から特徴を抽出して人間がわかりやすいようにしているだけなので、そんなものは OHLC + Volume をそのまま突っ込んで機械に特徴抽出させればいいと思っています。
もしかすると 300 日とか超長期の移動平均線の値は特徴量として有効かも知れません。これはいずれ試したいですね。
学習データの正規化/標準化
やると学習が安定するのでほぼ必須です。やり方は適当にググるか下記の本読んでください。ちなみに自分は下記の本読むまで正しい正規化/標準化ができていませんでした。
 Python機械学習プログラミング 達人データサイエンティストによる理論と実践 (impress top gear) www.amazon.co.jp
Python機械学習プログラミング 達人データサイエンティストによる理論と実践 (impress top gear) www.amazon.co.jp
欠損値の扱い
どんな方法であれ過去の価格データを取得してみるとだいたい欠損値があります。自前で MetaTrader とか cTrader 動かしてリアルタイムで数年かけてデータを取れば欠損のないデータが取れるとは思いますが、それだと時間がかかりすぎます。運用後についでに取っていくのはいいと思います。
価格データは連続したデータなので欠損値は補間するのがいいでしょう。補間する方法はいくつかありますが、欠損値の前の時間の価格で補間するのが妥当だと思われます。これは実際の為替市場で、取引が無い場合は前回の価格データがそのままその時間の価格データになるのと同じだからです。
RNN vs CNN
価格データは連続データなので RNN を使うのが良さそうに思えますが、最初にやった感じだと計算が遅すぎて正直厳しかったです。もっとも、Deep Learning やり始めのほうでやっただけなので、今の知見を以って改めて試すと違うかも知れないのでまた試したいですね。
現在は CNN でやっています。CNN といえば画像認識に使われることが多いのですが、自然言語処理とかにも使えます。それ同じようにして価格データを画像とみなして入力データにしています。
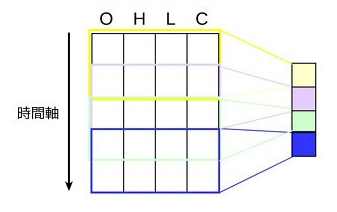
価格データをロウソク足チャートの画像にして CNN に食わせたことがありますが、ディスクアクセスすごいしデータはデカイし計算は遅いしでいいことありませんでした。
精度はどうなの

現状でベースラインから 17% ぐらいの精度は出ています。まだバックテストはしてないからなんとも言えないですが、教師データはスプレッドとかキツめに考慮したものを使っているので精度イコール利益になると思っています。ちなみに 買い 売り そのまま の 3 クラス分類です。
まとめ
Deep Learning で最初は全く精度出せなかったんですが、1 周回っていけそうだなという感じになってきました。他にも色々と試したいことが多いので、もうちょっと詳しい話はそのうちまた書くと思います。
あとどうでもいいんですが、Deep Learning は割と Trial and error の世界なので、プログラミングを始めた頃を思い出します。