相変わらず大して精度が出なくなったまま色々やってますが、まだいい感じにはなっていません。道のりは長いですね。では色々やったこと(の一部)を書きます。
Max Pooling を使わない
現在は下記のような自然言語処理に使う CNN でチャート情報をパターンとみなして予測を行っています。
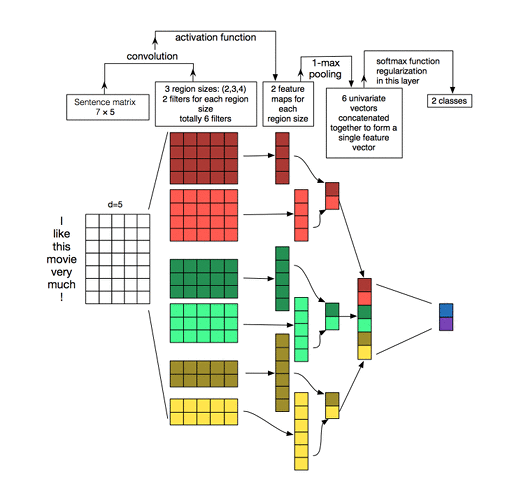
なので Max Pooling も掛けてるんですが、プーリングというのは、情報を圧縮して小さい変化を無視することによって頑健性を上げる効果があります。
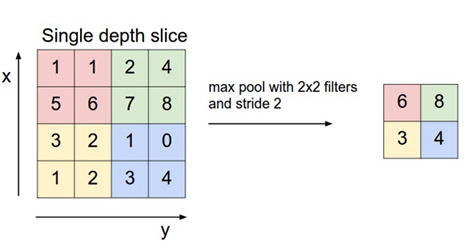
ですが、為替チャートに適用する場合、小さい変化を無視すると、同じパターンなのに結果が変わってしまうことがあるのではないかと考えました。要はプーリングによって情報が落ち、チャート A とチャート B が全く同じ特徴になったとき、チャート A は上がり、チャート B は下がったという場面だと上手く分類できなくなるのではないかということです。
適合率と再現率を指標に使う
現在は 買い 売り そのまま の 3 クラス分類でやってますが、これの評価には今までベースラインからどれぐらい予測精度が上がったかどうかというものを使ってきました。
例えば学習データが 買い = 10% 売り = 10% そのまま = 80% の比率だった場合、全て そのまま を選べば 80% の精度が出ることになります。一見高精度に見えますが、実際には何も予測していないのと同じです。これでは正しい評価ができません。
そこで、1 番確率の高いものをベースラインとして、それより何 % 良くなっているかで評価するようにします。前述の例ですと、80% をベースラインに設定します。Deep Learning で行った予測結果が 82% だったとします。この場合 82 - 80 = 2% となり、2% 精度が上がったとみなせます。
ですが、これも問題があります。それは 全ての予測結果 - ベースライン = 予測精度 となってしまうことです。極端な例だと、10% ある 買い を全て予測的中させていればこれ以上無い精度なのですが、売り と そのまま が共に全て外れていた場合、(買い精度 10% + 売り精度 0% + そのまま精度 0%) - ベースライン 80% = -70% となり、予測精度は -70% となってしまいます。そこでこの問題を解消するために適合率と再現率を評価として導入します。
適合率
適合率 (precision) は予測結果に対して、本当に正しかった予測の割合です。10 回 買い と予測して、そのうち 10 回全てが 買い だった場合の適合率は 100% です。いわゆる正確性です。
再現率
再現率 (recall) は予測するべきものの数のうち、実際に予測された数の割合です。学習データに 100 回 買い と予測するべきものがあるとして、そのうち 100 回全てを 買い として予測した場合の再現率は 100% です。いわゆる網羅率です。
為替予測で重視する指標
適合率と再現率はトレードオフの関係にあります。例えば学習データに 買い が 100 回、売り が 100 回ある場合を考えます。このとき、1 回だけ 買い と予測してそれが正解であれば適合率は 100% になりますが、再現率は 1% になります。また、200 回予測して全て 買い と予測すれば再現率は 100% になりますが、適合率は 50% になります。
為替予測においては再現率より適合率のほうが重要だと考えています。チャンスを全て拾おうとするよりも、少ないチャンスの中で確実に予測を当ててくれる方が収益が上げやすいからです。
5 分足データを使うようにする
1 分足データでやると 1 epoch 回すのに約 100 分かかってました。これを 5 分足データを使うようにして入力データの長さを 5 分足用に調整すると、1 epoch 約 100 秒で終わるようになりました。1 分足のほうがデータ量が多いので良いと思っていましたが、さすがにこの違いは大きいので 5 分足で epoch を重ねる方向にシフトしました。ざっと見た感じだと精度にそれほど違いが出てないように見えます。
まとめ
色々試行錯誤してるんですが、中々いい精度が出ません。そこそこの精度が出ても再現しません。パラメーターサーチであってもちゃんとチェックポイントを取っておくべきだと思います。現在は引き続き Deep Learning で上手く予測できるようになるかもしれないアイデアを考えつつ、強化学習で上手くできそうな方法はないかと模索しているところです1。K-means もまた試すかも。
-
強化学習は以前やってみて失敗しているので、そのときの結果を踏まえて色々考えています。 ↩︎